Wonderly's Github Blog
track of thoughts
study in community detection in network
Recently I’m thinking if I can find out any interest preference within a bunch of online novel reading logs. The idea is intuitive, people may be interested in some kind of novel like love story, magic, sci-fi or military etc. , then the the novels in the same kind may be read by a same person frequently than two novels out of the same kind. It seems easy to identify for coarse categories as I already have category tag for each of the novel, but identify interest within more subdivided categories or even within totally another kind of hierarchy of categories like interest of different ages seems to have much more fun.
The first thing comes into my head is using clustering, classical algorithms are hierarchical, k-means, canopy, Gaussian mixture model, Dirichlet process clustering, etc. The limitation is using only novel reading logs, novel can not be represented as point in space. In this case, k-means, center-based hierarchical and Gaussian mixture model is not suitable. In spite of this, normal cluster algorithm only considers links between 2 nodes, but rarely consider links among all nodes within a cluster.
Clustering Coefficient is a good way to describe the attribute of a cluster, but exhaustively enumerate all possible clusters and calculate clustering coefficient is clearly unacceptable.
the paper Finding and evaluating community structure in networks, MEJ Newman, M Girvan - Physical review E, 2004 - APS is trying to solve similar problem, and the features of its method is, first it’s an dividing method not an agglomerating method, second, it uses “betweenness” which is defined on an edge as weighted sum of shorted path between any 2 nodes passes through this edge, to divide the graph.
but it’s different from what I thought.
first, In real world, a node can belong to different communities at the same time
second, it’s fine some nodes are alone, or the cluster is very small, but the middle size clusters which is very cohesive is what I’m looking for. so I’m still prefer aggregating method of clustering.
Recently, I’m thinking through the clique method, it is:
- first generate all maximal cliques of the whole graph.
- second, use the maximal cliques as core and attach other nodes to a clique to form a cluster if the node is close enough to most of the nodes in the clique.
like the picture below, the red nodes and deep green nodes are 2 group of maximal cliques, and the orange nodes are attached to red clique to form a cluster, and grass green nodes are attached to deep green nodes to form another cluster. there are some white nodes which are not in any cluster, and the middle node have both orange and grass green belongs to both cluster
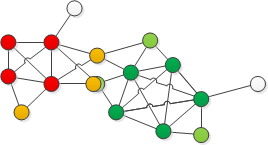
but the problem is finding clique is NP-Complete problem, when the graph is as large as social network, sequential method will be too slow. there are some useful thing I found:
- "On Computing All Maximal Cliques Distributedly",Fábio Protti, Felipe M. G. Fran?a, and Jayme Luiz Szwarcfiter , a divide and conquer method, recursively divide graphs into v1, v2, and computer cliques in v1, v2 and between v1, v2
- xrime, a graph algorithm package, which include a maximal clique method. It generates the neighbors of neighbors for each node, and find maximal clique in each set of neighbors of neighbors. the method is clean and tricky but to emit all adjacent list to all neighbors seems to be too heavy.